Технология OCR (оптическое распознавание символов) используется для получения текста из изображения или даже отсканированного документа. Он позволяет копировать текст с изображения для дальнейшего редактирования или печати. После того, как вы скопировали текст с картинки с помощью технологии OCR, вы можете вставить его в Блокнот, Wordpad или документ Microsoft Word для дальнейшего редактирования или печати.
PDF позволяет напрямую копировать текст, если он не защищен от записи или не преобразован в PDF из файла изображения. В Интернете доступно несколько хороших удобных бесплатных программ, которые помогают извлекать текст из файла изображения, например, Some PDF Images Extract. К вашему сведению, последняя версия программы Microsoft Word также может получать текст из файла изображения. Зато есть кеш. Сначала вам нужно преобразовать изображение в PDF, а затем вы можете получить текст из файла изображения, используя документ Microsoft Office Word.
FreeOCR
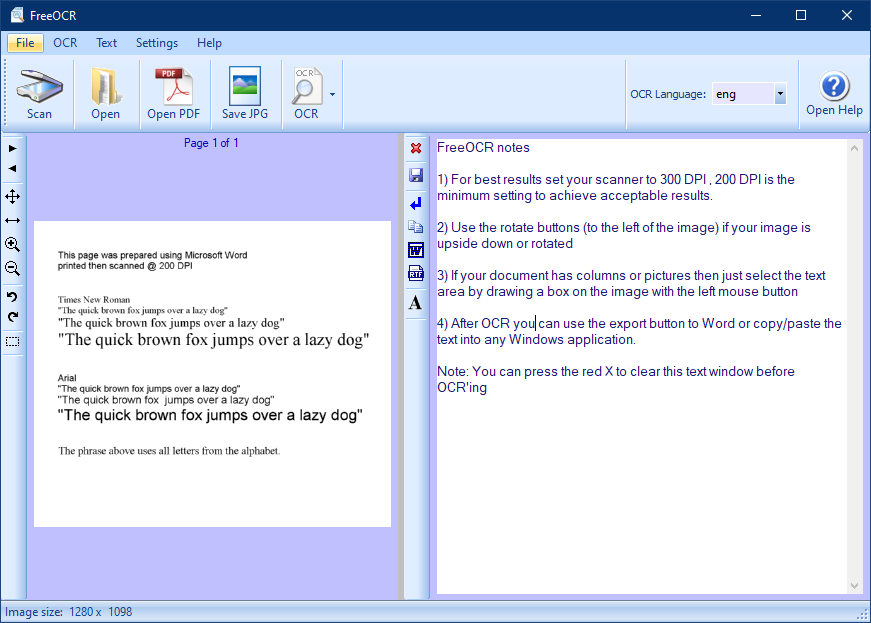
В этом посте мы собираемся представить новое бесплатное приложение, которое называется FreeOCR. Как следует из названия, FreeOCR — это бесплатная программа, которая поддерживает сканирование OCR. Он даже поддерживает сканирование большинства сканеров Twain, а также может открывать большинство отсканированных PDF-файлов, многостраничных изображений Tiff и популярных форматов файлов изображений. Он выводит обычный текст, который можно напрямую экспортировать в формат Microsoft Word. Если вы ищете инструмент OCR, который извлекает тексты из файлов изображений и PDF-файлов, FreeOCR может быть правильным выбором для этой работы.
Что касается совместимости, то он поддерживает все версии Windows, включая Windows 11, 8.1/8, 7, Vista и Windows XP. Я лично протестировал его с 64-разрядной версией Windows 11/10, и он работает без каких-либо проблем или проблем.
Шаг 1. Перейдите по ссылке на официальную веб-страницу и загрузите последнюю версию FreeOCR.
Шаг 2. Установите загруженный файл на свой ПК и запустите инструмент, дважды щелкнув его ярлык на рабочем столе.
Шаг 3. Вы можете выбрать сканер, изображение или файл PDF, чтобы получить тексты с помощью FreeOCR. Выберите соответствующую опцию на панели инструментов. В моем примере мы собираемся извлечь текст из файла изображения. Следовательно, будет нажимать на Открытым кнопку для изображения и выберите с нашего ПК.

Шаг 4. После импорта изображения или PDF-файла в приложение FreeOCR нажмите кнопку OCR. Выберите здесь «Распознавание текущей страницы” или же “Распознавание всех страниц” вариант в соответствии с вашими потребностями.

Шаг 5. Вы можете увидеть извлеченный текст на правой боковой панели этой бесплатной утилиты. Это позволяет вам копировать выходные тексты, которые вы можете вставить в любой блокнот, Wordpad или документ Microsoft Word.
Кроме того, вы можете напрямую отправить вывод в документе Microsoft Word или RTF, щелкнув его значок в центре приложения. Если вы хотите сохранить вывод в текстовом файле, щелкните значок «Сохранить» в середине этой программы.

Окончательное мнение о FreeOCR
В нашем тесте мы обнаружили, что FreeOCR работает без проблем на 64-разрядных компьютерах с Windows 10. Разработчик заявляет, что он совместим с Windows 10 (предварительная техническая версия), 8.1/8, 7, Vista и XP.
FreeOCR имеет удобный и современный дизайн. Он позволяет извлекать текст из изображения или PDF-файла. Даже вы можете напрямую подключать сканеры для прямого извлечения текста из отсканированного документа.
Скачать FreeOCR
Вы можете скачать эту бесплатную утилиту с официального сайта.