Следующая статья поможет вам: Эволюция НЛП: прошлое, настоящее и будущее
НЛП имеет дело с компьютерами, обрабатывающими человеческий язык. В этой статье мы объясним эволюцию НЛП и покажем вам, как НЛП стало неотъемлемой частью нашей жизни.
Оглавление
- Что такое обработка естественного языка?
- Эволюция обработки естественного языка
- Важность обработки естественного языка
Обработка естественного языка или НЛП — это раздел естественных языков и информатики, изучающий взаимодействие между человеческим языком и компьютерными системами. Эта область также известна как компьютерная лингвистика и искусственный интеллект в лингвистической области.
NLP в первую очередь относится к приложениям обработки естественного языка на таких языках, как английский или французский, в первую очередь для использования людьми. Но с развитием NLP появились новые потенциальные приложения для обработки естественного языка в таких областях, как анализ правоохранительных органов с криминальными профилями, медицинская диагностика и лечение с помощью персонализированных медицинских панелей.
{kind=link}
Это уже не просто академическая теория — она повсюду. Он стал достаточно повсеместным в наших системах развлечений, образования и многих других областях, где мы ежедневно используем технологии. В этой статье мы рассмотрим эволюцию НЛП с 1940-х годов до наших дней.
Что такое обработка естественного языка?
Человеческий язык — очень сложная и уникальная способность, которой обладают только люди. Существуют тысячи человеческих языков с миллионами слов в наших словарях, где несколько слов имеют несколько значений, что еще больше усложняет ситуацию.
Компьютеры могут выполнять несколько высокоуровневых задач, но единственное, чего им не хватает, — это способности общаться, как люди. НЛП — это междисциплинарная область искусственного интеллекта и лингвистики, которая устраняет разрыв между компьютерами и естественными языками.
Есть бесконечные возможности для расположения слов в предложении. Практически невозможно сформировать базу данных всех предложений языка и загрузить ее в компьютеры. Даже если бы это было возможно, компьютеры не могли бы понять или обработать то, как мы говорим или пишем; язык не структурирован для машин.
Поэтому очень важно преобразовывать предложения в структурированную форму, понятную компьютерам. Часто встречаются слова с несколькими значениями (словаря недостаточно, чтобы устранить эту двусмысленность, поэтому компьютеры также должны изучать грамматику), и произношение слов также различается в зависимости от региона.
{kind=link}
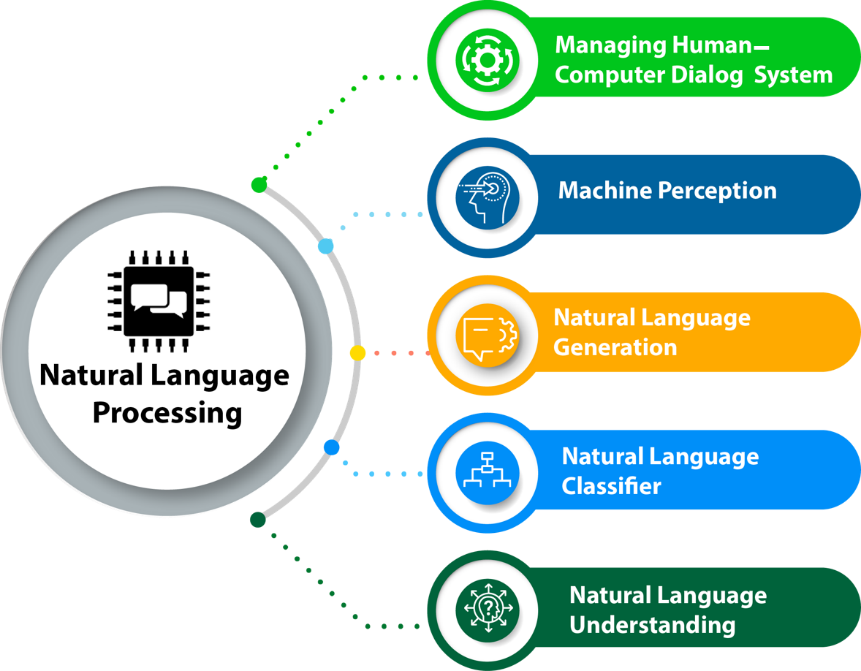
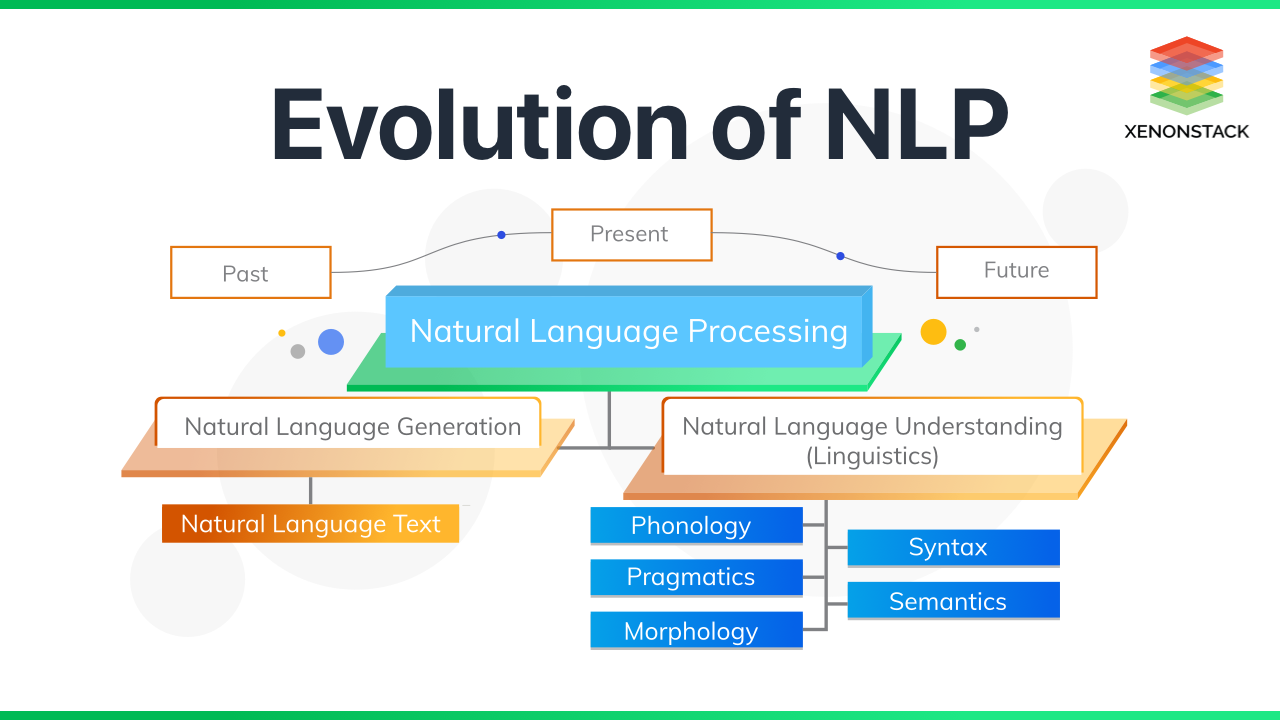
Функция НЛП состоит в том, чтобы переводить структурированный и неструктурированный текст; таким образом помогая машинам понимать человеческий язык. Когда вы переходите от неструктурированной к структурированной форме (превращая естественный язык в информативное представление), это называется пониманием естественного языка (NLU).
Это известно как генерация естественного языка (NLG), когда вы переходите от структурированного к неструктурированному (производя значимые фразы из внутреннего представления).
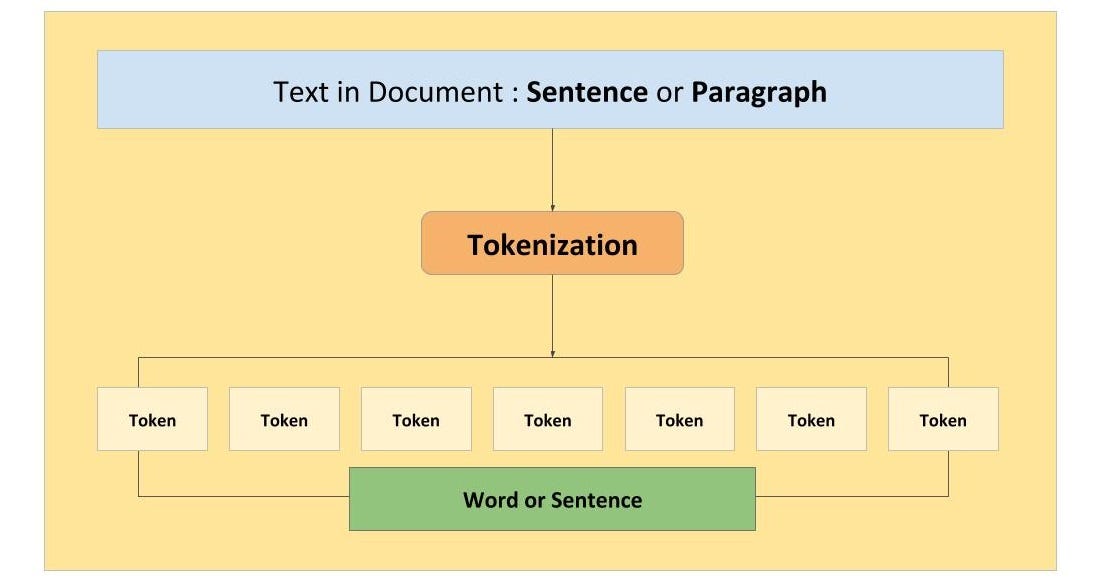
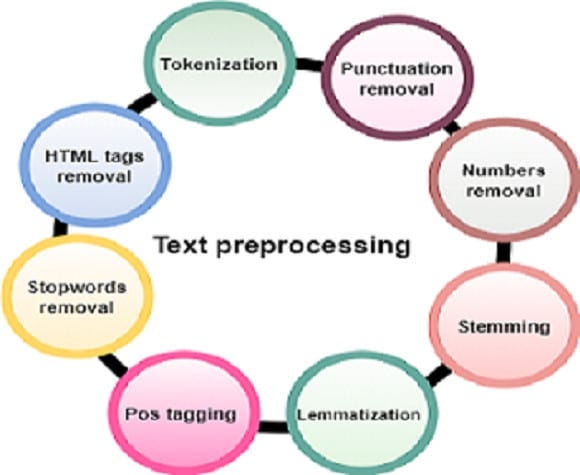
- Первый этап называется токенизацией. Строка слов или предложений разбивается на компоненты или токены. Это сохраняет суть каждого слова в тексте.
{kind=link}
- Следующим шагом является определение основы, когда из слов удаляются аффиксы для получения основы. Например, слова «бежит», «бежит» и «бег» имеют одну и ту же основу «бег».
- Лемматизация – следующий этап. Алгоритм ищет значение слова в словаре, и определяется его корневое слово, чтобы получить его значение в соответствующем контексте. Например, корень слова «лучше» не «ставка», а «хорошо».
- Некоторые слова имеют несколько значений, которые зависят от контекста текста. Например, во фразе «позвони мне» «позвони» — это существительное. Но в «позвонить врачу» «позвонить» — это глагол. На этом этапе NLP анализирует положение и контекст маркера, чтобы определить правильное значение слов, что называется тегированием частей речи.
{kind=link}
- Следующий этап известен как «распознавание именованных объектов». На этом этапе алгоритм анализирует объект, связанный с токеном. Например, токен «Лондон» связан с местоположением, а «Google» — с организацией.
- Разделение на фрагменты — это заключительный этап обработки естественного языка, который выбирает отдельные фрагменты информации и группирует их в более значимые части.
Все эти функции выполняются в NLTK, инструменте, разработанном Python. Все процессы NLP и анализ текста используют эту библиотеку инструментов естественного языка.
Эволюция обработки естественного языка
{kind=link}
Эволюция НЛП — это непрерывный процесс. Самая ранняя работа НЛП началась с машинного перевода, который был упрощенным по своему подходу. Идея заключалась в том, чтобы преобразовать один человеческий язык в другой, и началась она с преобразования русского языка в английский. Это привело к преобразованию человеческого языка в компьютерный язык и наоборот.
В 1952 году Bell Labs создала первую систему распознавания речи Audrey. Он мог распознавать все десять цифровых цифр. Однако от него отказались, потому что вводить телефонные номера пальцем было быстрее. В 1962 году IBM продемонстрировала машину размером с обувную коробку, способную распознавать 16 слов.
{kind=link}
DARPA разработало Harpy в Университете Карнеги-Меллона в 1971 году. Это была первая система, которая распознавала более тысячи слов. Эволюция обработки естественного языка набрала обороты в 1980-х годах, когда распознавание речи в реальном времени стало возможным благодаря достижениям в вычислительной производительности.
Были также инновации в алгоритмах обработки человеческих языков, которые отказались от жестких правил и перешли к методам машинного обучения, которые могли учиться на существующих данных естественных языков.
Ранее чат-боты были основаны на правилах, где эксперты кодировали правила, сопоставляя, что может сказать пользователь, и какой должен быть соответствующий ответ. Однако это был утомительный процесс и давал ограниченные возможности.
{kind=link}
Ранним примером НЛП, основанного на правилах, была Элиза, созданная Массачусетским технологическим институтом в 1960 году. Элиза использовала синтетические правила для определения смысла в письменном тексте, который он переворачивал и спрашивал пользователя.
Конечно, эволюция НЛП произошла за последние пятьдесят лет. Разделы вычислительной грамматики и статистики дали НЛП другое направление, породив области статистической обработки языка и извлечения информации.
С развитием НЛП системы распознавания речи используют глубокие нейронные сети. Разные гласные или звуки имеют разные частоты, которые можно различить на спектрограмме.
Это позволяет компьютерам распознавать произносимые гласные и слова. Каждый звук называется фонемой, и программы распознавания речи знают, как эти фонемы выглядят. Наряду с анализом разных слов НЛП помогает определить, где начинаются и заканчиваются предложения. И в конечном итоге речь преобразуется в текст.
Синтез речи дает компьютерам возможность выводить речь. Однако эти звуки прерывисты и кажутся роботизированными. Хотя это было очень заметно в машине с ручным управлением от Bell Labs, сегодняшние компьютерные голоса, такие как Siri и Alexa, улучшились.
{kind=link}
Сейчас мы наблюдаем взрыв голосовых интерфейсов на телефонах и автомобилях. Это создает положительную обратную связь с людьми, которые чаще используют голосовое взаимодействие, что дает компаниям больше данных для работы.
Это обеспечивает лучшую точность, что приводит к тому, что люди больше используют голос, и цикл продолжается.
Эволюция НЛП происходила семимильными шагами за последнее десятилетие. НЛП, интегрированное с глубоким и машинным обучением, позволило чат-ботам и виртуальным помощникам выполнять сложные взаимодействия.
Чат-боты теперь работают за пределами области взаимодействия с клиентами. Они также могут справиться с человеческими ресурсами и здравоохранением. НЛП в здравоохранении может отслеживать лечение и анализировать отчеты и медицинские записи. Когнитивная аналитика и НЛП объединяются для автоматизации рутинных задач.
{kind=link}
Эволюция НЛП происходила со временем и развитием языковых технологий. Специалисты по данным разработали несколько мощных алгоритмов; некоторые из них следующие:
- Пакет слов: эта модель подсчитывает частоту каждого уникального слова в статье. Это делается для того, чтобы научить машины понимать сходство слов. Однако миллионы отдельных слов содержатся в миллионах документов; следовательно, сохранение таких обширных данных практически невообразимо.
- TF-IDF: TF (частота терминов) рассчитывается как количество раз, когда определенный термин появляется из числа терминов, присутствующих в документе. Эта система также исключает «стоп-слова», такие как «is», «a», «the» и т. д.
- Матрица совместного появления: эта модель была разработана, поскольку предыдущие модели не могли решить проблему семантической неоднозначности. Он отслеживал контекст текста, но требовал много памяти для хранения всех данных.
- Модели-трансформеры: это модель кодировщика и декодера, которая использует внимание для более быстрого обучения машин, имитирующих человеческое внимание. BERT, разработанный Google на основе этой модели, феноменально революционизировал НЛП.
Университет Карнеги-Меллона и Google разработали XLNet, еще одну модель на основе сети внимания, которая предположительно превзошла BERT в 20 задачах. BERT экспоненциально улучшил результаты поиска в браузерах. Мегатрон и GPT-3 основаны на этой архитектуре, используемой в синтезе речи и обработке изображений.
В этой модели кодер-декодер кодер сообщает машине, что она должна думать и запоминать из текста. Декодер использует эти мысли, чтобы принять решение о подходящем ответе и действии.
Например, в предложении «Мне бы хотелось клубники___». Идеальные слова для этого бланка — «торт» или «молочный коктейль». В этом предложении кодировщик фокусируется на слове клубника, а декодер извлекает нужное слово из группы терминов, связанных с клубникой.
- Будущие предсказания НЛП
НЛП развивается каждую минуту по мере накопления все большего количества неструктурированных данных. Таким образом, нет конца эволюции обработки естественного языка.
{kind=link}
- По мере того, как будет генерироваться все больше и больше данных, НЛП займется анализом, осмыслением и хранением данных. Это поможет цифровым маркетологам анализировать гигабайты данных за считанные минуты и соответствующим образом разрабатывать маркетинговую политику.
- НЛП занимается человеческим языком. Тем не менее, эволюция НЛП в конечном счете привнесет в свою область невербальные коммуникации, такие как язык тела, жесты и выражения лица.
Для анализа невербальной коммуникации НЛП должно иметь возможность использовать биометрические данные, такие как распознавание лиц и сканер сетчатки глаза. Точно так же, как НЛП умеет понимать чувства, стоящие за предложениями, оно в конечном итоге сможет читать чувства, стоящие за выражениями. Если такая интеграция между биометрией и НЛП произойдет, взаимодействие между людьми и компьютерами приобретет совершенно новый смысл.
- Следующим масштабным шагом в области ИИ станет создание гуманоидной робототехники путем интеграции НЛП с биометрией. Благодаря роботам взаимодействие компьютера и человека перейдет в общение человека и компьютера. Визуальные помощники даже не начинают охватывать сферу НЛП в будущем. В сочетании с достижениями в области биометрии эволюция НЛП может создать роботов, которые могут видеть, осязать, слышать и говорить, как люди.
- НЛП будет формировать коммуникационные технологии будущего.
Важность обработки естественного языка
НЛП решает основную проблему машин, не понимающих человеческий язык. По мере своего развития НЛП превзошла традиционные приложения, а искусственный интеллект используется для замены человеческих ресурсов в нескольких областях.
{kind=link}
Давайте посмотрим на важность НЛП в современном цифровом мире:
- «Машинный перевод» — важное применение НЛП. NLP стоит за широко используемым Google Translate, который преобразует один язык в другой в режиме реального времени. Он помогает компьютерам понимать контекст предложений и значение слов.
{kind=link}
- Виртуальные помощники, такие как Cortana, Siri и Alexa, являются благом эволюции НЛП. Эти помощники понимают, что вы говорите, дают соответствующие ответы или совершают соответствующие действия, и все это делается с помощью НЛП.
- Интеллектуальные чат-боты берут штурмом мир обслуживания клиентов. Они заменяют человеческую помощь и разговаривают с клиентами так же, как это делают люди. Они интерпретируют письменный текст, и в соответствии с этим он определяет действия. НЛП — это рабочий механизм таких чат-ботов.
- НЛП также помогает в анализе настроений. Он распознает настроение, стоящее за сообщениями. Например, он определяет, является ли отзыв положительным, отрицательным, серьезным или саркастическим. Механизмы НЛП помогают таким компаниям, как Twitter удалить твиты с нецензурной бранью и т.д.
{kind=link}
- NLP автоматически сортирует наши электронные письма по категориям социальных сетей, рекламных акций, входящих сообщений и спама. Эта задача НЛП известна как классификация текста.
- Другие важные аспекты НЛП проявляются в проверке правописания, исследовании ключевых слов и извлечении информации. Программы проверки на плагиат также работают в программах НЛП.
- НЛП также управляет рекламными рекомендациями. Это соответствует рекламе с нашей историей.
- НЛП помогает машинам понимать естественные языки и выполнять задачи, связанные с языком. Это позволяет компьютерам анализировать больше языковых данных, чем люди.
Невозможно понять эти ошеломляющие объемы неструктурированных данных, доступных обычными средствами. Вот где на помощь приходит НЛП. Эволюция НЛП позволила машинам без устали структурировать и анализировать текстовые данные.
- Язык состоит из миллионов слов, нескольких диалектов и тысяч грамматических и структурных правил. Важно понимать синтетический и семантический контекст человеческого текста, что невозможно для компьютеров.
НЛП жизненно важен в этом свете, поскольку помогает разрешить любую двусмысленность, связанную с естественными языками, и добавляет ценную числовую структуру к информации, которую могут обрабатывать машины. Некоторыми примерами являются распознавание речи и текстовая аналитика.
Заключение
Таким образом, NLP обрабатывает естественные языки, такие как Lego, и делает компьютеры способными понимать и обрабатывать человеческие языки. Это позволяет машинам отвечать на вопросы и подчиняться командам.
Виртуальные помощники являются наиболее показательным вкладом в обработку естественного языка и показывают, насколько далеко продвинулась эволюция НЛП. Изучая эволюцию NLP, специалисты по данным могут предсказать, какую форму примет эта увлекательная ветвь IA в будущем.
Можно с уверенностью заключить, что речевые технологии станут такой же популярной формой взаимодействия с компьютерами, как клавиатуры, экраны и другие устройства ввода-вывода, которыми мы пользуемся сегодня.
Часто задаваемые вопросы
1. Есть ли будущее у НЛП?
эволюция НЛП происходит в этот самый момент. НЛП развивается с каждым твитом, голосовым поиском, электронной почтой, сообщением в WhatsApp и т. д. MarketsandMarkets установили, что НЛП будет расти со среднегодовым темпом роста в 20,3% к 2026 году. По данным Statistica, рынок НЛП будет процветать 14 раз в период с 2017 по 2025 год.
2. В чем основная проблема НЛП?
Неоднозначность языка, такая как семантическая, синтаксическая и прагматическая, является самой большой проблемой, которую необходимо преодолеть НЛП для точной обработки естественных языков.
3. Является ли НЛП наукой о данных?
НЛП — увлекательная и бурно развивающаяся область науки о данных. Это меняет то, как мы взаимодействуем с машинами и по-другому используем речевые технологии.
4. Каковы подполя обработки естественного языка?
В НЛП есть два подполя: понимание естественного языка (NLU) и генерация естественного языка (NLG).
5. Какова цель НЛП?
Ученые данных разработали NLP, чтобы позволить машинам интерпретировать и обрабатывать человеческие языки. С развитием НЛП теперь оно может взаимодействовать и с людьми. Siri и Alexa — некоторые примеры последних применений НЛП.