Этот сайт может получать партнерские комиссии по ссылкам на этой странице. Условия использования  Hot Chips 31 находится на этой неделе, с презентациями от нескольких компаний. Intel решила использовать высокотехнологичную конференцию для обсуждения нескольких продуктов, включая ключевые сессии, посвященные отделу искусственного интеллекта компании. Искусственный интеллект и машинное обучение считаются важными областями для будущего вычислительной техники, и хотя Intel управляет этими областями с помощью таких функций, как DL Boost в Xeon, она также разработала ускорители специально для рынка.
Hot Chips 31 находится на этой неделе, с презентациями от нескольких компаний. Intel решила использовать высокотехнологичную конференцию для обсуждения нескольких продуктов, включая ключевые сессии, посвященные отделу искусственного интеллекта компании. Искусственный интеллект и машинное обучение считаются важными областями для будущего вычислительной техники, и хотя Intel управляет этими областями с помощью таких функций, как DL Boost в Xeon, она также разработала ускорители специально для рынка.
NNP-I 1000 (Spring Hill) и NNP-T (Spring Crest) предназначены для двух разных рынков: вывод и обучение. «Обучение» – это работа по созданию и обучению нейронной сети, как обрабатывать данные в первую очередь. Логический вывод относится к задаче фактического выполнения модели нейронной сети, которая сейчас обучается. Для обучения нейронной сети требуется гораздо больше вычислительной мощности, чем для применения результатов обучения в реальной задаче категоризации или классификации.
Intel Spring Crest NNP-T разработан для разработки на беспрецедентном уровне с балансом между вычислительной мощностью натяжителя, пакетом HBM, пропускной способностью сети и интегрированной SRAM для повышения производительности обработки. Базовый чип был построен TSMC, да, TSMC, при 16 нм, с размером матрицы 680 мм2 и чередователем 1200 мм2. Полный блок имеет 27 миллиардов транзисторов со стеком памяти HBM2-2400 4×8 ГБ, 24 тензорными группами обработки (TPC) с частотой ядра до 1,1 ГГц. Шестьдесят четыре линии SerDes HSIO обеспечивают совокупную полосу пропускания 3, 58 Тбит / с, а карта поддерживает соединения PCIe x16 4.0. Потребляемая мощность оценивается в 150-250 Вт. Этот чип построен с использованием усовершенствованного пакета CoWoS TSMC (Chip-on-Wafer-on-Substrate) и содержит 60 МБ кэш-памяти, распределенной по нескольким ядрам. CoWoS конкурирует с Intel EMIB, но Intel решила построить это оборудование на TSMC вместо использования собственного литейного производства. Урожайность оценивается в 119 ТОПов.
«Мы не хотим растрачивать пространство на то, что нам не нужно», – сказал вице-президент Intel по аппаратному обеспечению Кэри Клосс. «Наш набор инструкций прост: умножение матриц, линейная алгебра, свертка. У нас нет собственных записей, все они являются тензорами (2D, 3D или 4D)». В программном обеспечении определено много вещей, включая возможность программирования То же самое, когда ломаешь модель, чтобы выполнить или выключить кости. «Думайте об этом как об иерархии», – сказал Клосс в интервью. «Вы можете использовать один и тот же набор инструкций для перемещения данных между двумя группами в группе рядом с HBM или между группами или даже умереть в сети. Мы хотим упростить то, что программное обеспечение управляет связью».
Слайд-шоу ниже показывает шаги архитектуры NNP-T. Все данные принадлежат Intel, а показатели производительности, представленные в микробенчмарке компании, явно не были проверены ExtremeTech.

NNP-T разработан для эффективного выхода без необходимости в шасси. Несколько ускорителей NNP-T могут быть подключены к одному шасси, и карты поддерживают шасси с шасси и даже бесклеевые соединения от стойки к стойке без необходимости в коммутаторах. На задней панели каждой промежуточной платы есть четыре сетевых порта QFSP (Quad Small Form Factor Pluggable).
У нас до сих пор нет данных о производительности, но это высококачественная учебная карта, которую Intel будет продавать, чтобы конкурировать с такими людьми, как Nvidia. До сих пор неясно, как окончательные решения, такие как Xe, которые не будут поставляться в центры обработки данных до 2021 года, войдут в будущий портфель продуктов компании после появления на рынке центров обработки данных и тензоров GPU.
Спринг Хилл / NNP-I: Icelake на борту
Spring Hill, новый ускоритель вывода Intel, – это совершенно другое животное. Если NNP-T предназначен для силовых конвертов мощностью 150-250 Вт, NNP-I – это секция мощностью 10-50 Вт, предназначенная для подключения к гнезду M.2. Он имеет два ядра процессора Koreake в паре с 12 механизмом вычисления вывода (ICE).
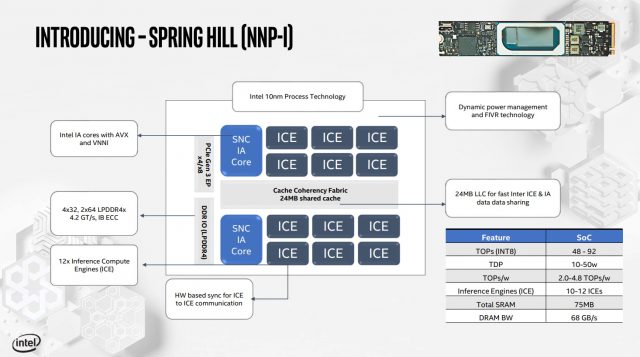
Машины A12 ICE и ядра с двумя ЦП совместимы с согласованным 24 МБ LMB и совместимы с инструкциями AVX-512 и VNNI. Существует два встроенных контроллера памяти LPDDR4X, которые подключены к неработающему пулу памяти LPDDR4 (о емкости пока ничего не известно). Пропускная способность DRAM до 68 ГБ / с, но общий объем DRAM на карте неизвестен. Spring Hill можно добавить к любому современному серверу, поддерживающему слоты M.2. Согласно Intel, устройство взаимодействует через лифт M.2 как продукты PCIe, а не через NVMe.
Целью NNP-I является выполнение операций на процессорах AI с меньшими затратами ресурсов основного процессора в системе. Устройство подключено через PCIe (совместим с PCIe 3.0 и 4.0) и обрабатывает AI-нагрузки, используя ядро матрицы Koreake для необходимой обработки. SRAM и DRAM в массиве обеспечивают пропускную способность локальной памяти.
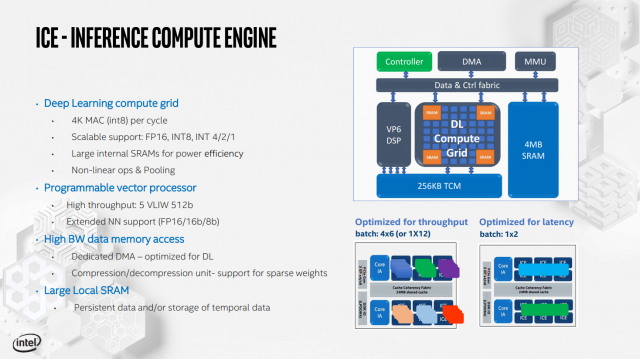
Inference Compute Engine поддерживает множество форматов команд, от FP16 до INT1, с программируемым векторным процессором и 4 МБ SRAM для каждого отдельного ICE.
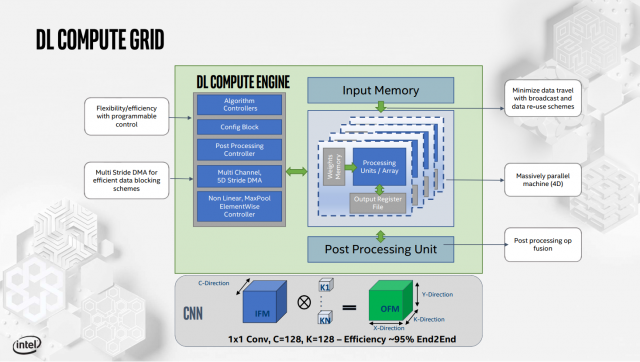
Также имеется натяжной двигатель, называемый Deep Learning Compute Grid и Tensilica Vision P6 DSP (используется для обработки рабочих нагрузок, которые не настроены для работы на фиксированной вычислительной сетке DL).
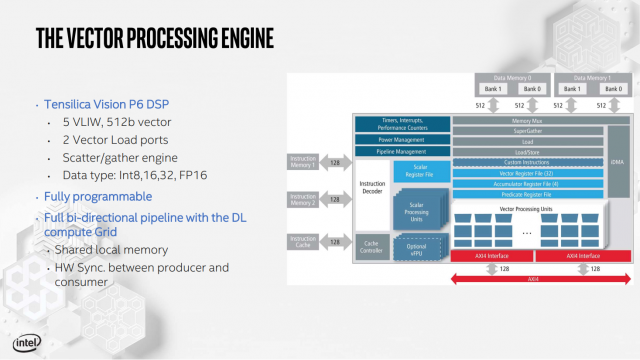
Вся подсистема памяти NNP-I также оптимизирована: кэш L3 разделен на восемь сегментов по 3 МБ, разделенных между ядром ICE и процессором. Цель состоит в том, чтобы данные были как можно ближе к элементам обработки, которые в них нуждаются. Intel утверждает, что NNP-I может предложить такую высокую производительность ResNet50, как 3600 выводов в секунду при работе на TDP 10 Вт. Он работал до 4,8 TOPS / ватт, что соответствует общим целям эффективности Intel (компания заявляет, что NNP-I более эффективен при меньших ваттах).
Корпорация Intel не ожидает, что NNP-I выйдет на розничный рынок, но решения по логическому выводу делают бизнес быстрее по сравнению с высококачественными решениями для учебных центров. NNP-I можно отправить нескольким клиентам за короткое время, в зависимости от общего поглощения.
Оба решения призваны бросить вызов Nvidia в дата-центре. Хотя они сильно отличаются от Xeon Phi, можно утверждать, что они все вместе направляются в пространство, которое Intel Xeon Phi хочет продать, хотя и совсем другим способом. Но это не всегда плохо: когда создавался оригинальный Larrabee, идея использовать GPU для работы с искусственным интеллектом и центрами обработки данных была мощной концепцией. Анализ проблем с новой специальной архитектурой для вывода и обучения – это разумный шаг для Intel, если компания может взять объемы Nvidia.
Сейчас читаю:
Add comment