 Большая часть нашего охвата GPU сфокусирована на потребительской стороне бизнеса и тестах игры, но я обещаю еще раз проверить вычислительную сторону производительности, когда выйдет Radeon VII. С недавно выпущенным 5700 XT у нас есть шанс вернуться к этому вопросу с новой архитектурой графического процессора AMD и сравнить RDNA с GCN.
Большая часть нашего охвата GPU сфокусирована на потребительской стороне бизнеса и тестах игры, но я обещаю еще раз проверить вычислительную сторону производительности, когда выйдет Radeon VII. С недавно выпущенным 5700 XT у нас есть шанс вернуться к этому вопросу с новой архитектурой графического процессора AMD и сравнить RDNA с GCN.
Фактически, вся вычислительная ситуация находится на интересном перекрестке. AMD заявила, что они хотят быть более серьезными игроками в вычислительной среде компании, но также сказала, что GCN будет продолжать существовать с RDNA в этом пространстве. Radeon VII – это вариант потребительского дросселя AMD MI50 с поддержкой среднескоростной FP64. Например, если вам нужны FP64-вычисления с двойной точностью, Radeon VII заполняет нишу так, как это не делают другие графические процессоры в этом сравнении.
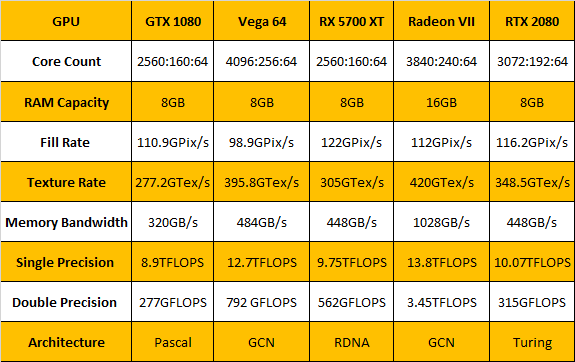
Radeon VII имеет самую высокую пропускную способность ОЗУ, и это единственный графический процессор в этом сравнении, который предлагает множество форм производительности с двойной точностью. Но хотя эти графические процессоры имеют относительно схожие спецификации на бумаге, между ними существуют существенные различия с точки зрения производительности, и цифры не всегда совпадают с тем, что вы думаете.
Одна из главных тем разговоров AMD с 5700 XT Navi теперь является принципиально новой архитектурой графического процессора. 5700 XT оказывается быстрее, чем Vega 64 в нашем тесте уравнения на стороне потребителя, но мы также хотим изучить ситуацию в области вычислений. Однако, пожалуйста, обратите внимание, что новый 5700 XT здесь тоже немного пагубен. Некоторые приложения могут нуждаться в обновлении, чтобы в полной мере использовать их возможности.
Navi теперь является принципиально новой архитектурой графического процессора. 5700 XT оказывается быстрее, чем Vega 64 в нашем тесте уравнения на стороне потребителя, но мы также хотим изучить ситуацию в области вычислений. Однако, пожалуйста, обратите внимание, что новый 5700 XT здесь тоже немного пагубен. Некоторые приложения могут нуждаться в обновлении, чтобы в полной мере использовать их возможности.

О Блендере 2.80
Наши результаты испытаний содержат данные Blender 2.80 и независимые тесты Blender, 1.0beta2 (выпущены в августе 2018 года). Blender 2.80 является основной версией приложения и содержит несколько существенных изменений. Независимые тесты не совместимы с семейством Nvidia RTX, которое требует тестирования с использованием последней версии программного обеспечения. Изначально мы тестировали бета-версию Blender 2.80, но последняя версия вышла из строя, поэтому мы отказались от результатов бета-тестирования и провели повторную проверку.
Блендер изображение
Существует значительная разница в производительности между тестами Blender 1.0beta2 и 2.80, и одна сцена, Classroom, не отображается правильно в новой версии. Эта сцена была удалена из сравнения 280 нам. Blender позволяет пользователям определять размеры мозаики в пикселях, чтобы контролировать, сколько сцен обрабатывается одновременно. Код в эталонном файле Python Blender 1.0beta2 показывает, что в тестах используется размер плитки 512 × 512 (координаты X / Y) для графического процессора и 16 × 16 для процессора. Большинство файлов сцены фактически содержатся в Однако в тесте по умолчанию используется размер плитки 32 × 32, если он загружен в Blender 2.80.
Мы тестировали Blender 2.80 в двух разных режимах. Сначала мы протестировали все поддерживаемые сцены, используя стандартные размеры листов, заполненных этими сценами. Это 16 × 16 для Barbershop_Interior и 32 × 32 для всех других сцен. Затем мы протестировали тот же рендеринг со стандартным размером плитки 512 × 512. До сих пор правило с размерами плитки было то, что большие размеры хороши для графических процессоров, а меньшие размеры хороши для процессоров. , Кажется, это что-то меняет с Blender 2.80. Графические процессоры AMD и Nvidia демонстрируют совершенно разные реакции на большие размеры мозаики: графические процессоры AMD ускоряются при увеличении размеров мозаики, а графические процессоры Nvidia теряют производительность.
Поскольку файлы сцены, которые мы тестировали, были созданы в более ранней версии Blender, это могло повлиять на наши общие результаты. Мы интенсивно работали с AMD в течение нескольких недель, чтобы изучить аспекты производительности Blender на графических процессорах GCN. GCN, Pascal, Turing и RDNA демонстрируют разные шаблоны результатов, варьирующиеся от 32 × 32 до 512 × 512, при этом Turing теряет более низкую производительность, чем Pascal и RDNA, получая большую производительность в большинстве случаев, чем GCN.
Все наши графические процессоры получают большую выгоду от нет используя размер плитки 16 × 16 для Barbershop_Interior. Хотя этот тест по умолчанию 16 × 16, он не очень хорошо работает с размерами тайлов на любом графическом процессоре.
Решите проблему, связанную с различными результатами, которые мы видели в бета-тесте Blender 1.0Beta2 по сравнению с бета-тестированием Blender 2.80, и, наконец, в окончаниях Blender 2.80 этот обзор был запущен уже несколько недель, и мы подменили некоторые драйверы AMD, работая над ним. Поэтому все результаты Blender 2.80 мы запускаем с Adrenaline 2019 Edition 19.8.1.
Настройки теста и заметки
Все графические процессоры протестированы на системах Intel Core i7-8086K с материнскими платами Asus Prime Z370-A. Vega 64, Radeon RX 5700 XT и Radeon VII протестированы с Adrenaline 2019 Edition 19.7.2 (7/16/2019) для всего но Блендер 2.80. Все тестирование Blender 2.80 выполняется с использованием 19.8.1 или 19.7.2. Nvidia GeForce GTX 1080 и Gigabyte Aorus RTX 2080 тестируются с использованием драйвера Nvidia 431.60 Game Ready (23.07.2009).
CompuBench 2.0 проводит графические процессоры через серию тестов, предназначенных для измерения различных аспектов его вычислительной производительности. Тем не менее, Кишонти, разработчик CompuBench, похоже, не предлагает существенных подробностей о том, как они разработали свои тесты. Моделирование заданного уровня может относиться к использованию заданного уровня для анализа поверхности и формы. Подразделение Catmull-Clark – это техника, используемая для создания гладких поверхностей. Моделирование N-тела – это моделирование динамических систем частиц под воздействием таких сил, как гравитация. Оптический поток TV-L1 является реализацией метода оценки оптического потока, который используется в компьютерном зрении.
Рабочая станция SPEC 3.1 содержит множество тех же самых рабочих нагрузок, что и SPECViewPerf, но также имеет дополнительные вычислительные рабочие нагрузки на GPU, которые мы опишем отдельно. Полную информацию о тестовой рабочей станции и наборе приложений можно найти здесь. Рабочая станция SPEC 3.1 работает в своем первоначальном тестовом режиме 4K. Хотя этот анализ не был направлен в SPEC для официального опубликования, наше тестирование рабочей станции SPEC 3.1 соответствует установленным в организации правилам тестирования, которые можно найти здесь.
NVIDIA GPU всегда тестируется с CUDA, когда CUDA доступен.
Мы подготовили для вас два набора результатов: серию синтетических тестов, выполненных с помощью SiSoft Sandra и исследующих различные аспекты сравнения этих чипов, в том числе вычислительную мощность, задержку памяти и внутренние характеристики, а также набор более обширное тестирование, которое касается вычислений и рендеринга. Производительность в различных приложениях. Поскольку тесты SiSoft Sandra 2020 являются исключительными для приложения, мы решили разбить их на собственное слайд-шоу.
Результаты Gigabyte Aorus RTX 2080 следует считать примерно эквивалентными RTX 2070S. Оба графических процессора работают практически одинаково на рабочих нагрузках потребителей и должны также соответствовать друг другу на рабочей станции.
SiSoft Sandra 2020
SiSoft Sandra – это полнофункциональный универсальный пакет утилит для оценки и оценки производительности. Хотя это синтетический тест, это может быть полнофункциональная утилита для синтетической оценки, и Адриан Силаси (Adrian Silasi), разработчик, потратил десятилетия на ее исправление и исправление, добавляя новые функции и тестируя по мере разработки CPU и GPU.
Конкретные результаты нашей SiSoft Sandra приведены ниже. Некоторые из наших результатов OpenCL немного странны, когда дело доходит до 5700 XT, но, по словам Адриана, у него не было возможности оптимизировать код, который будет работать на 5700 XT. Думайте об этих результатах как о предварительных, интересных, но, возможно, еще не доказанных, когда дело доходит до графических процессоров.
Наши тесты SiSoft Sandra 2020 идут в основном в одном направлении. Если вам нужна плавающая точка двойной точности, Radeon VII – компьютерный монстр. Хотя неясно, сколько покупателей попадает в эту категорию, есть определенные места, такие как обработка изображений и высокоточные рабочие нагрузки, где сияет Radeon VII.
Radeon 5700 XT на основе RDNA не сильно отличается в этом тесте, но мы также имели дело с Silasi относительно проблем, с которыми мы столкнулись во время тестирования. Большая поддержка может изменить некоторые из этих результатов в ближайшие месяцы.
Результаты теста
Теперь, когда мы обсудили производительность Сандры, давайте перейдем к остальной части нашей справочной серии. Другие наши результаты включены в слайд-шоу ниже:
заключение
Что эти результаты передают нам? Многие вещи довольно интересные. Во-первых, RDNA действительно впечатляет. Помните, что мы протестировали этот графический процессор в профессиональном и ориентированном на компьютер приложении, ничего не было обновлено или исправлено для запуска. Есть явные признаки того, что это влияет на результаты наших тестов, включая некоторые тесты, которые не выполняются или работают медленно. Тем не менее, 5700 XT впечатляет.
Radeon VII потрясающий. также, но по-другому, чем 5700 XT. SiSoft Sandra 2020 показывает, что превосходство этой карты может генерировать рабочую нагрузку с двойной точностью, где она обеспечивает гораздо большую производительность, чем все остальное на рынке. В последнее время искусственный интеллект и машинное обучение стали намного важнее, но если вы работаете в области, где графические процессоры с двойной точностью являются ключевыми, Radeon VII обладает достаточной огневой мощью. SiSoft Sandra не включает тесты, которые зависят от D3D11 вместо OpenCL. Но поскольку OpenCL является основным конкурентом CUDA, я решил продолжать использовать его во всех случаях, кроме тестов на задержку памяти, которые в глобальном масштабе показывают меньшую задержку для всех графических процессоров при использовании D3D по сравнению с OpenCL.
Ранее AMD заявляла, что намерена сохранить GCN на компьютерном рынке, а Navi ориентирована на потребительский рынок, но нет никаких признаков того, что компания намерена продолжать разработку GCN по отдельному пути от RDNA. Более вероятное значение для этого заключается в том, что GCN не будет заменен на вершине компьютерного рынка, пока Big Navi не будет готова где-то в 2020 году. Исходя из того, что мы видели, есть много вещей, которые следует рассмотреть в этом направлении. Уже есть приложения, в которых RDNA значительно быстрее, чем Radeon VII, хотя между картами существуют большие различия с точки зрения возможностей двойной точности, пропускной способности ОЗУ и объема памяти.
Blender 2.80 представляет серию интересных сравнений между РДНК, GCN и CUDA. Использование большего размера мозаики оказывает большое влияние на производительность графического процессора, но хорошее или плохое различие зависит от марки используемого графического процессора и семейства включенных архитектур. Графические процессоры Pascal и Turing лучше всего работают с меньшими размерами листов, а графические процессоры GCN лучше работают с большими размерами. Размер плитки 512 × 512 лучше в целом для всех графических процессоров, но только потому, что он увеличивает общее время рендеринга в Barbershop_Interior больше, чем это, он портит время рендеринга любой другой сцены для графических процессоров Тьюринга и Паскаля. RTX 2080 является самым быстрым графическим процессором в нашем тесте Blender, но 5700 XT обеспечивает превосходные общие результаты производительности.
Я не хочу делать глобальные заявления о настройках Blender 2.80; Я не эксперт в 3D-рендеринге. Результаты этого теста показывают, что Blender лучше всего работает с большими настройками мозаики в AMD, но меньшие настройки мозаики могут дать лучшие результаты для графических процессоров Nvidia. В прошлом графические процессоры AMD и Nvidia извлекали выгоду из больших размеров тайлов. Однако этот шаблон также может быть связан с конкретными сценами, о которых идет речь. Если вы запускаете Blender, я предлагаю вам поэкспериментировать с различными сценами и размерами плиток.
В конечном итоге эти результаты показывают, что на некоторых из этих профессиональных рынков производительность графических процессоров гораздо больше, чем мы ожидаем. Существуют специальные тесты, в которых 5700 XT значительно быстрее, чем RTX 2080 или Radeon VII, и другие тесты, где он сильно отстает. Незрелость драйвера OpenCL может быть причиной этого, но мы видим вспышку яркости в этой проблеме производительности. Производительность Radeon VII с двойной точностью ставит его в отдельный класс в определенных вопросах, но Radeon RX 5700 XT – намного более дешевая и тихая карта. В зависимости от целей вашего приложения, новый графический процессор за 400 долларов может стать лучшим вариантом на рынке. В другом сценарии Radeon VII и RTX 2080 предъявляют особые и особые требования в качестве самых быстрых доступных карт.
Представленное изображение является последним рендерингом сцены Benchmark_Pavilion, включенной в эталонный тест карты Blender 1.02.
Сейчас читаю:
Add comment